*이번 포스팅의 내용은 졸업프로젝트 수업 중에 진행한 특강의 내용을 정리한 것이다.
오늘 졸업프로젝트 수강 시간에 강사님이 오셔서 kaggle에 대한 특강을 진행해주셨다. 수업 시작 전 kaggle.com에 들어가서 미리 가입을 해두었다.
캐글 사이트에 들어가면 오른쪽 위에 register이 있다. 이 버튼을 눌러 새로 가입을 할 수 있는데 이때 이름을 영어로 설정해줘야 가입이 된다!
가장 위 search 칸에 walmart store를 쳐서 Competitions 쪽에 있는 Walmart Recruiting - Store Sales Forecasting을 클릭해준다. 월마트의 부서 별 판매량을 예측하는 대회이다.

들어가면 이런 식으로 페이지가 뜨는데 Description에서 이 대회에 대한 설명을 볼 수 있고 Evaluation에서 평가 기준을 확인할 수 있다. 우리는 이것을 캐글을 사용해 예측해볼 것이기 때문에 상단 Notebook 탭에 들어갔다.

오른쪽 New Notebook을 눌러주면 새 코드를 실행할 수 있다. 아래에는 다른 사람들이 올려놓은 코드들이다. 처음 캐글을 실행하는 거라면 핸드폰 인증을 진행해야한다. +82 찾아서 선택해주고 번호 입력 후 인증하면 된다.
New Notebook을 클릭해 새로운 코드를 열어보면 기본 코드가 떠 있는데 이건 캐글에서 제공해주는 코드다. 처음에 이걸 실행시키면 필요한 파일의 경로를 쉽게 확인할 수 있고, numpy와 pandas가 import된다. shift+enter를 눌러 한 번 실행시켜주고 아랫줄부터 분석에 필요한 코드를 작성했다.
1. 데이터 불러오기
우선 train data와 test data를 불러와서 변수에 각각 저장해준다. pd.read_csv() 함수를 사용하면 csv 형식의 파일을 저장할 수 있다. 괄호 안에는 해당 파일의 경로를 넣어준다. zip 형식이더라도 파일이 하나만 있다면 관계없다고 말씀하셨다. train과 test에 데이터를 저장하고 나서 밑에 한 번씩 적어주면 train과 test를 출력해볼 수 있다.
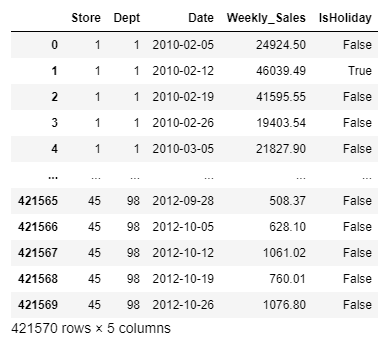
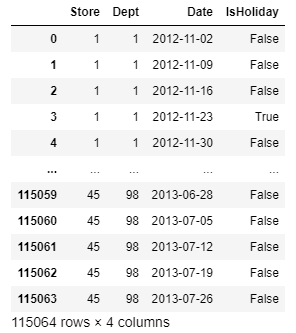
이렇게 train과 test에 데이터가 잘 들어간 것을 확인할 수 있고, 동시에 각각 어떤 column들이 몇 개나 존재하는지도 알 수 있다.
2. 데이터 전처리
다음으로 데이터 전처리를 해줘야한다. 사실 오늘 진행한 예시는 딥러닝이 아니라 머신러닝 예시다. 미리 파일을 정형화시켜서 모델에 제공을 해줄 필요가 있기 때문에 데이터 전처리를 진행했다. 데이터 전처리에서는 크게 두 가지 단계가 필요한데 첫번째는 숫자형식이 아닌 column을 숫자로 바꿔주거나, 삭제하는 것이다. 따라서 train.dtypes 명령을 한 번 실행해 column들의 타입을 확인한 뒤에 숫자형식이 아닌 Date column을 삭제할 필요가 있다.
두 번째 전처리는 바로 train과 test의 column 개수를 맞춰주는 것이다. test의 출력결과를 보면 Weekly_Sales column이 존재하지 않는다는 것을 알 수 있다. Weekly_Sales는 이 test의 정답에 해당하는 부분이기 때문에 test set에는 포함되지 않는 것이다. 따라서 train에서는 Date와 Weekly_Sales를 삭제하고, test에서는 Date를 삭제해준다.
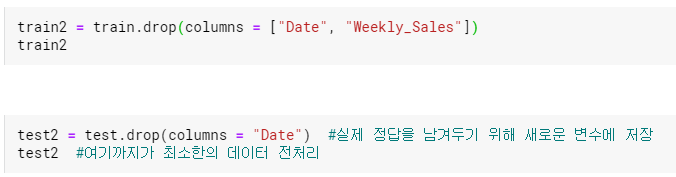
이렇게 drop함수를 사용하여 해당 column을 삭제해주었다. column 여러개를 삭제하고 싶다면 반드시 대괄호를 사용하여 적어주어야한다. 대괄호는 여러 column에 접근하거나, 특정 column에 접근하고자 할 때 사용할 수 있다. 삭제할 때 주의할 점은 정답을 따로 남겨두어야하기 때문에 삭제하는 data는 새로운 변수에 저장을 해줘야한다는 점이다. 그냥 drop을 해버리면 삭제된 파일은 저장이 되지 않는다.
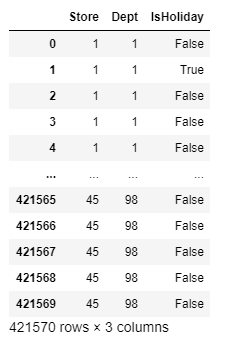
실행을 시켜보면 이런 식으로 Date와 Weekly_Sales 항목이 삭제된 것을 알 수 있다. 이렇게 하면 최소한의 전처리가 끝난다.
3. 모델링
이제 모델을 적용하여 실행을 해보면 된다. 이번 특강에서는 RandomForest 모델을 사용하였다. RandomForest에는 크게 두 가지 종류가 있는데 하나는 RandomForestClassifier이고, 다른 하나는 RandomForestRegressor이다. Classifier는 말 그대로 어떤 분류를 할 때 사용하는 것이다. 예를 들어 참/거짓을 판별한다던가... 그런 식의 예측에 필요하고 Regressor는 "양적인" 예측에 적합한 모델이다. 예측하고자하는 결과값이 한 주의 판매량이었기 때문에 Classifier 대신에 Regressor를 사용하였다.

RandomForestRegressor를 불러와 변수에 저장해주는데 이때 괄호 안에 n_jobs를 적어주면 사용할 CPU의 개수를 지정할 수 있다. kaggle에서는 사용자 당 최대 4개의 CPU를 지원해준다고 한다. 따라서 제일 많이 사용하고 싶다면 4를 적어도 되고, 최댓값을 의미하는 -1을 적어주어도 된다.
fit을 사용하여 모델을 훈련시키는데 이때 왼쪽에는 학습시킬 데이터가, 오른쪽에는 정답값을 넣어주어야한다. 아까 전처리를 해둔 train2를 학습시킬 데이터로 넣고 오른쪽엔 정답값인 train의 Weekly_Sales column을 넣어준다. 특정 column에 접근하는 것이기 때문에 대괄호를 넣어줘야한다.

모델을 학습시키고 나서 test에 대한 실제 예측을 하기 위해 result라는 변수에 test2에 대한 예측 결과를 저장해주었다. 이 부분을 실행시키면 test2에 대한 weekly sales 예측값이 result에 저장된다.
위쪽 코드 맨 윗줄의 %%time은 이 부분의 코드를 수행하는데 걸린 시간을 재주는 기능을 한다. 이유는 모르겠지만 %%time 옆에 주석을 적으면
UsageError: Can't use statement directly after '%%time'!
이런 에러가 뜬다. 주석을 지우거나 다른 코드 뒤에 적어주면 해결된다.
4. 결과 저장 및 제출
이제 예측한 결과값을 제출물의 형태에 맞게 저장한 후, 제출해야한다. 이런 대회들의 제출물 형태는 sampleSubmission 파일을 통해 확인할 수 있고 기본 제공되는 파일이다. train, test와 마찬가지로 맨 처음 코드에서 그 경로를 알 수 있다.
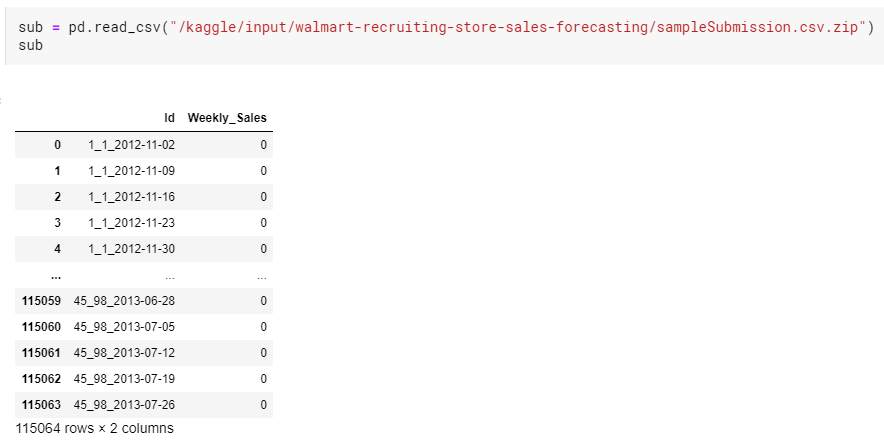
첫 부분 코드와 동일하게 파일을 불러와 실행을 시켜보았다. 제출해야하는 데이터는 이런 형식이고, Weekly_Sales 부분에 예측한 결과값을 넣어주면 된다.
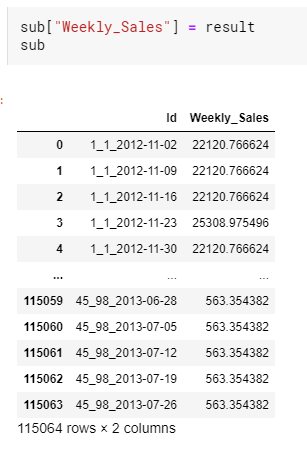
sub 파일의 Weekly Sales column에 접근해서 result 값을 넣어주고 출력하면 아까와 달리 값이 들어간 것을 확인할 수 있다. 이제 이 sub 변수를 다시 csv 파일로 저장한 후에 제출을 하면 된다.

아주 간단하다... read_csv 대신에 to_csv를 써주고 왼쪽에 파일 이름, 오른쪽에 index = False 혹은 index = 0이라고 적어준다. index는 왼쪽의 쭉 적혀있는 0~115063 숫자들을 의미한다. 이 숫자를 column에 포함할건지에 대한 부분인데, False로 설정하지 않으면 기본으로 index = True로 설정되어 저 column이 포함되게 된다. 하지만 제출형식에 index는 포함되지 않았으므로 index를 만들지 않기 위해 index = False라는 옵션을 넣어주어야 한다.
오른쪽 Data 탭을 보면 output에 sub.csv 파일이 추가된 것을 확인할 수 있다. 여기에 마우스를 올리면 점 세 개가 뜨는데 그 버튼을 눌러 다운로드 받을 수 있다. 다운로드 받은 후에, input 아래에 있는 walmart-recruiting...여기에 마우스를 올리면 똑같은 점 세 개가 뜨는데 메뉴 중에 Open in new tab을 클릭하면 아까 봤던 페이지를 새로운 탭에서 띄워준다. 이 대회는 이미 끝난 대회이기 때문에 late submission을 눌러준다.
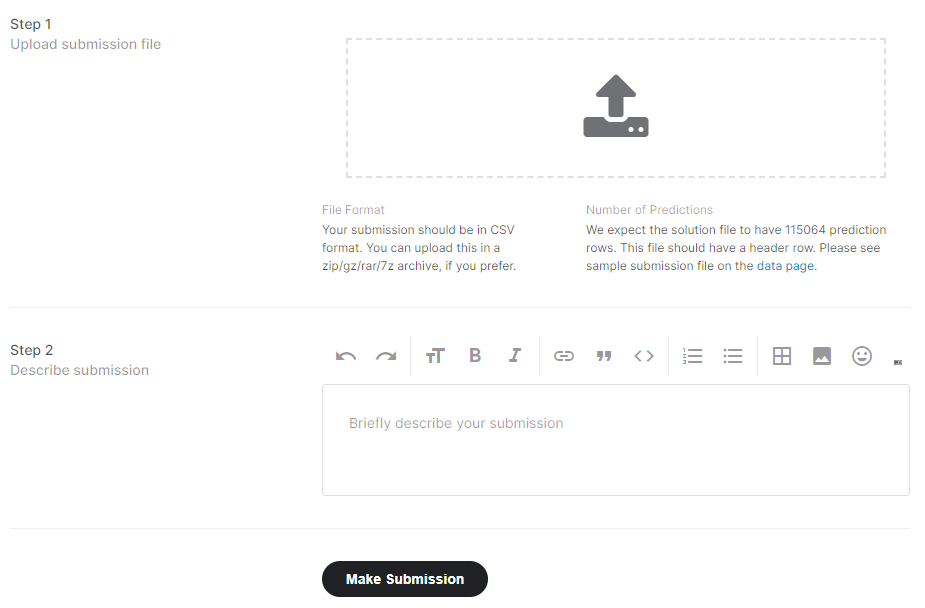
Step 1 부분에 아까 다운받은 sub.csv 파일을, Step 2에 파일에 대한 설명을 짧게 적은 후 Make Submission을 누르면 자동으로 점수를 매겨준다.

이런 식으로 제일 오른쪽에 점수가 나오는데 내가 이때 제출한 결과물은 Date column을 반영한 상태였기 때문에 결과가 더 좋게 나왔다. Date column을 반영하지 않는다면 대충 4800점대가 나온다. 이 Score는 평가 방식에 따라 높은 게 좋을 수도, 낮은 게 좋을 수도 있는데 이 대회에서는 실제 값과 예측 값의 차이를 더한 것이기 때문에 점수가 낮을 수록 높은 등수가 나온다. Leaderboard 메뉴에 가면 실제 대회에서 사람들이 몇 점을 받았는지 알 수 있다.
다음 포스팅에서는 이 모델의 점수를 향상시키는 방법에 대해서 적을 예정이다.
*kaggle 기본 단축어
alt+enter 코드 실행+아래에 코드 작성
shift+enter 코드 실행
esc 해당 코드 선택
(esc 누른 후) f 특정 단어 찾아서 변경
shift+tab(2초 정도) 해당 함수의 형식? 확인 가능
tab 사용 가능한 함수나 라이브러리 표시(첫글자는 입력해야함)
'딥러닝 스터디' 카테고리의 다른 글
| [kaggle] 캐글 기초와 bike sharing demand 분석 (0) | 2021.04.21 |
|---|---|
| [kaggle] 캐글 기초와 walmart sales 예측(2) - 모델 정확도 향상시키기 (0) | 2021.03.10 |
| 딥러닝 스터디2 (0) | 2021.01.06 |
| keras CNN 모델 파라미터 최적화 및 결과 (0) | 2020.11.23 |
| keras 사용한 CNN 모델 구축 (0) | 2020.11.19 |